I was recently challenged to apply image matting to the CelebA dataset. If that doesn’t ring a bell, matting is the art of separating a subject from its background. Your intuition is probably telling you that’s something you’d do with Photoshop, and you’d be right. It then shouldn’t be a surprise that Adobe released a paper in 2017 on training a network that does exactly this. I thought it’d be interesting to quickly cover what they propose, how I implemented it, and spend some time on the results. If you really want a painfully detailed write-up, check out my Jupyter notebook on it (warning: it’s really damn long).
Foundations: segmentation
Let’s build up an intuitive understanding of what we’re trying to do here. You’re probably familiar with image segmentation: the network detects various things in an image, and colors pixels based on that what type of thing it thinks it is. We could apply this as a first step to the challenge: can a network reliably segment the human foreground from the base class (background)?

You’ll notice it’s not a terribly convincing performance though: the cut-out looks super blocky. That’s because the segmentation is essentially binary: either it’s the human/foreground (1), or it’s the background (0). This is especially too coarse when you’re trying to segment thin parts like hair or fur.
Introducing trimaps
Okay, so what if we make it a bit more subtle: we’ll continue to do segmentation, but now there’s three classes: background, foreground and uncertain. The first two classes get the easy work, while the uncertain class contains the edge of our subject. At a later stage, we could for example just set the “uncertain” area to half transparency, which would make the edge less brutal. We call this a trimap, where the “tri” part refers to the three classes. They’ll be fundamental to the approach the DIM paper takes.

Intermezzo: alpha layers
The standard images you and I know, like .jpgs, have three channels: Red, Green and Blue (RGB). You’ll probably also have come across 4-channeled images, like .png for example. These have an additional channel, Alpha. Alpha is different, because it doesn’t talk about the color of the pixel. Instead, it essentially states how “transparent” a pixel should be. If it’s 1, it is fully visible, while at 0, it is fully transparent and shows the background (whatever that may be). Any value in between essentially lets the background “shine through”. Often a company’s logo will have this.
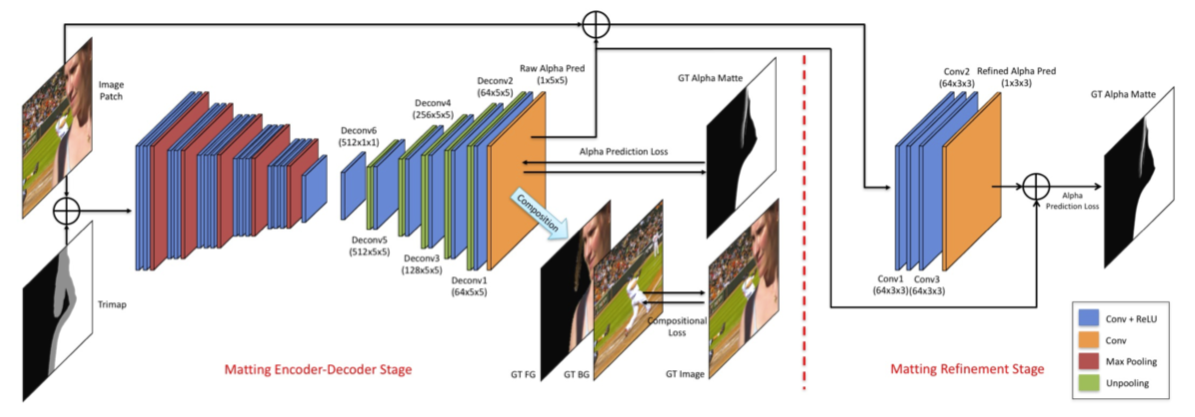
Deep Image Matting
Alright, so what does the paper propose? The paper proposes a network in two parts:
- Matting Network: The Matting Network is essentially a U-net, everyone’s favorite segmentation architecture. The network is fed an image and its corresponding trimap. It is subsequently trained to predict a rough corresponding alpha layer using an MSE Loss (the loss is actually more sophisticated than just MSE, but it would take me a separate post to go into the details).
- Refinement Network: The researchers discovered that the Matting Network tends to just predict a lot of semi-transparent pixels because it doesn’t “dare” to set some pixels fully to 0 or 1. Therefore, they tack on a 3-layer fully convolutional net to kind of “refine” those smooth edges into harder ones.
My Approach
My approach was trained using the SegmentAI dataset. This is a dataset that contains 40k images of humans with an alpha layer that separates them from their background, ideal for my challenge.

Armed with this dataset, I proceeded to do the following:
- Predicting trimaps: After manually converting the SegmentAI alpha layers into trimaps (using openCV erode and dilate), I trained a default U-net to learn to predict trimaps (standard segmentation application).
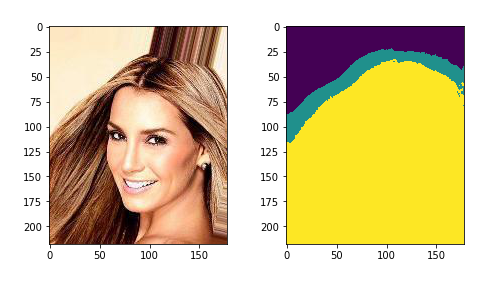
- Predicting rough alphas: I then trained a new U-net to take in a 4-channel image (standard RGB image + trimap on the A-channel) and spit out a single-channel rough alpha.
- Refining the alphas: Lastly, I fed all these RGB images and their new rough alphas through a standard 3-layer CNN to refine the predictions a bit.

Results
Let’s run the model on some CelebA samples and see how it does.

That’s mildly disappointing. Some thoughts:
- The trimaps are the main issue. When the trimap is decent, the resulting mat is pretty good too (see second-to-last row).
- Shadows are a problem. It looks like the trimap segmentation especially struggles with dark backgrounds and lacking contrast. Anywhere there’s shadows/dark backgrounds, the trimap is all over the place.
- More data wouldn’t hurt. The paper trained on 50k images, I trained on only 15k (Google Colab limits training times). Maybe the additional images could help with learning to deal with backgrounds?
- Better data wouldn’t hurt either. AISegment data is a good start, but it’s definitely not perfect (see sample posted at the top of this post).